
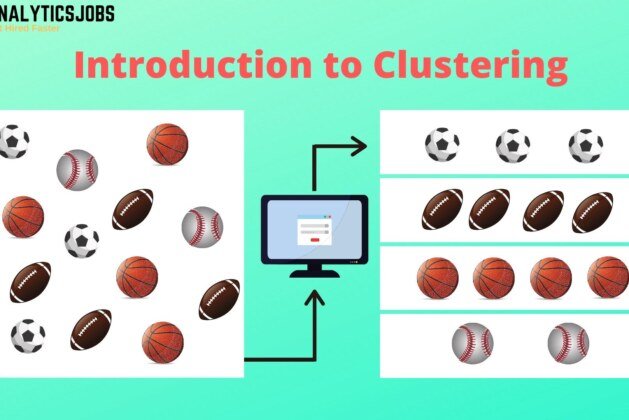
Clustering is a type of Unsupervised learning method. Clustering is a Machine Learning method that involves the grouping of data points. Provided a set of data points, to classify each data point into a specific group we can use clustering algorithms. Theoretically, data points that are in the same group need to have very similar properties and/or features, while data points in different groups must have highly dissimilar properties and/or features. Clustering is a common method for statistical data analysis used in several fields.
It is a collection of objects based on similarity and dissimilarity between them. In the past decade, Data had been increasing rapidly, when it comes to different forms of images, texts, files, videos, audio, etc. Clustering in machine learning uses the data to solve the questions.
For example: Detecting skin diseases
The doctor will use clustering algorithms to understand the marks on the skin and will predict what kind of disease it is. Clustering algorithms are used to group unlabeled data sets.
In data science, clustering analysis can be used to gain valuable insights from our data by seeing in which group the data point falls into when we apply a clustering algorithm.
For example: In the graph given below
The data points are clustered together and can be grouped, one single group. The clusters can be distinguished and a total number of clusters can be determined.

In the above graph, there are 3 clusters, it can be of any size.
Working of Clustering in Machine Learning
In clustering, we group an unlabeled data set. When we initially group unlabeled data, we have to find a similar group. When we make a group, we have to recognize the features of datasets i.e. data which is similar. In case we make a group by one or more features, it’s easy to evaluate similarity. There are no criteria for a good cluster, it totally depends on the users i.e. what parameters they may use that satisfy there needs.
Once clustering is done, a cluster number is assigned to each cluster known as ClusterID. ClusterID is used to represent complex data more easily. For example J
- YouTube uses the user’s search or watched history and suggests videos we might like.
- Amazon uses the buying pattern of the users and based on that gives suggestions like “people who purchased this product also bought this” and 40% of its revenue is generated by suggestions.
Types of clustering in machine learning
- Hard clustering
In hard clustering, a group of similar data points belonging to a single cluster. If the new data points are not similar up to a certain condition, the data points are completely removed from the cluster.
- Soft clustering
In soft clustering, relaxation is provided to every data entity which finds an equivalent like-hood data entity to form a cluster. In this type of clustering, a unique data entity is found in multiple clusters based on their like-hood.
Applications of Clustering in Machine Learning
- Healthcare
Doctors use a clustering algorithm to obtain the detection of disease. Let us take an example of thyroid disease. The thyroid disease dataset could be identified using a clustering algorithm whenever we apply unsupervised learning on a dataset that contains thyroid and non-thyroid datasets. Clustering will recognize the cause of disease and can provide a successful result search.
- Marketing
We can see or even observe that various technology is developing beside us and users are attracting to use those technologies like digital advertising, cloud. To attract a large number of customers every company is developing easy to use technology and features. Clustering is used to better understand customers. Clustering will help the company to understand the users and then categorize each customer. By doing this we can understand the consumer better and find similarities between customers and group them.
- Social Network
We are the generation of the internet era, we can get the details of any person through the internet. Social networking sites use clustering for content understanding, face recognition or the location of the end-user. When unsupervised learning is used in social networks, it’s beneficial for the translation of language. For example, Facebook and Instagram provide the option of translation of language.
Google is the most used search engine by users. Have you ever searched for some information on Google like “petrol pump near me”, Google will show the petrol pump near your location. This is done by clustering, clustering of similar results that are shown to you.
- Banking
We’ve observed that fraud of money is taking place around us and the company is warning people about it. With the assistance of clustering, insurance companies can detect fraud, acknowledge users about it and fully understand policies brought by the users.
There are various Algorithms in Clustering. Every Data Scientist and Data Scientist Aspirant should know about these algorithms… Click Here…

